一、背景
云原生时代下,k8s、微服务、devops大行其道,虽然说开发一个web应用的门槛越来越低,但随着应用的增长和架构膨胀,对生产环境的性能和稳定性的要求也越来越高。一套完备的监控告警体系,对微服务架构中服务治理来说就必不可少了。 Prometheus(普罗米修斯),由前google工程师从2012年开始在Soundcloud以开源软件形式进行研发的系统监控和告警工具包,是目前社区非常热门的开源监控告警解决方案。
客户ES搜索上线后,通过kafka中间件进行数据同步时经常会出现报错,为了更直观统计错误数量及错误类型,于是使用了框架内集成的prometheus客户端进行指标数据metrics上报。
二、是什么
prometheus(普罗米修斯),由前google工程师从2012年开始在Soundcloud以开源软件形式进行研发的系统监控和告警工具包,是目前社区非常热门的开源监控告警解决方案。
三、优势及功能
- 易于管理,无依赖存储,支持本地和远程
- 基于pull架构方式进行数据拉取
- 强大的数据模型,指标以metrics name和一组labels(k/v)作唯一标识存储在时序序列数据库(TSDB)
- 灵活的查询语言PromQl,可实现对监控数据的查询、聚合,可被应用在数据可视化和告警中
- 单实例可处理每秒数十万的数据点
- 多语言客户端集成
- 自带可直接查询的ui,也可被应用到其他可视化工具
四、基础架构
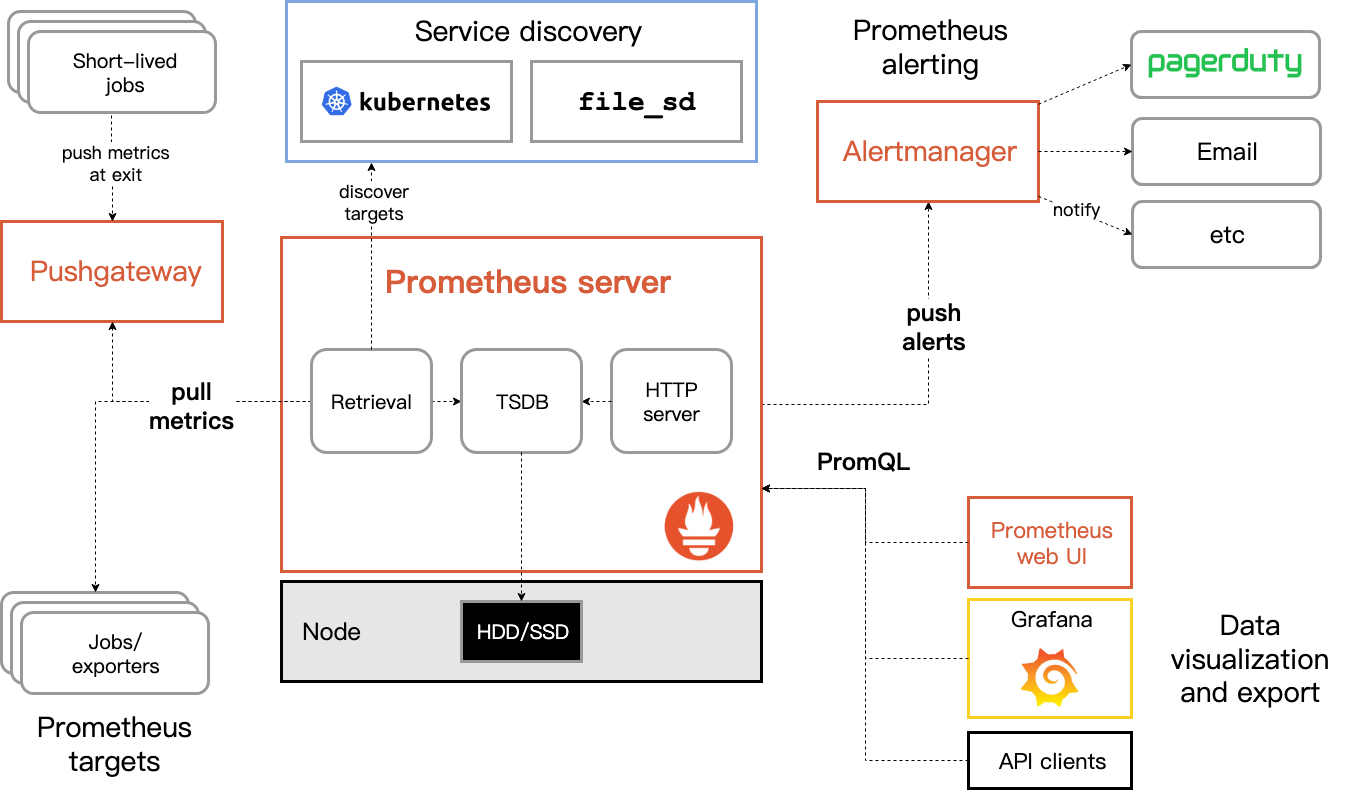
从这个架构图可以看出prometheus模块主要包含:server、exporters、pushgateway、PromQl、alertmanager、webui等
大概使用逻辑是:
1、client向targets(exporters)发送指标数据;
2、prometheus server定期从服务发现的exporters(如果无法直接访问则从pushgateway)中拉取pull指标数据;
3、拉取到的数据会存储在TSDB中,如果大于配置的内存缓存区时会将数据持久化到磁盘(使用remote storage会持久到云端)
4、如果配置了aletrule,prometheus会周期性的对告警规则进行计算,满足触发条件时会向alertmanager发送告警信息
5、alertmanager收到告警信息,可以对告警信息进行去重、分组、抑制以及静默等
6、可以通过api、prometheus web ui、grafna对指标数据进行查询、聚合
核心组件
prometheus server
负责从exporters抓取指标数据并存储,对外提供查询接口,触发告警规则
client libraries
对接prometheus server,查询、上报数据
pushgateway(server无法直接访问的情况下)
- 汇总exporters采集到的监控数据
- 收集短时间任务的metrics
- 最终由server统一收集
exporter
数据采集器,以http服务形式暴露给server,可以是一个独立运行的程序独立于监控目标以外,也可以是直接内置在监控目标中:
1、集成到应用:这一类Exporter直接内置了对Prometheus监控的支持,比如cAdvisor,Kubernetes,Etcd,Gokit等,都直接内置了用于向Prometheus暴露监控数据的端点;
2、独立使用/外部系统:原有监控目标并不直接支持Prometheus,因此我们需要通过Prometheus提供的Client Library编写该监控目标的监控采集程序,将监控对象的状态数据转成prometheus监控指标。例如: Mysql Exporter,JMX Exporter,Consul Exporter等。
alertmanager
接收prometheus server触发的告警,进一步处理之后进行告警通知
数据模型
时间序列
样本数据以时间序列的形式保存在内存数据库中,并定时刷新到硬盘上,时间序列是按照时间戳和值的序列方式存放的,我们可以称之为向量(vector),每一条时间序列都由一个指标名称和一组标签(键值对)来唯一标识
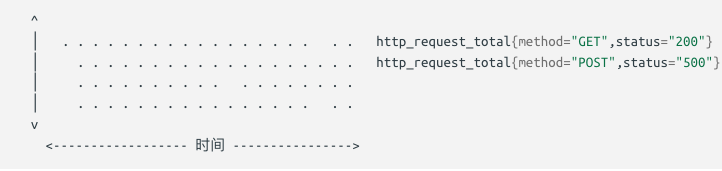
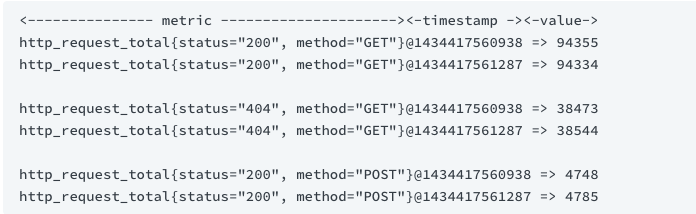
指标
1 | |
指标的名称(metric name)可以反映被监控样本的含义 标签(label)反映了当前样本的特征维度,通过这些维度Prometheus可以对样本数据进行过滤,聚合等。标签的名称只能由ASCII字符、数字以及下划线组成并满足正则表达式[a-zA-Z_][a-zA-Z0-9_]*。 其中以__作为前缀的标签,是系统保留的关键字,只能在系统内部使用。标签的值则可以包含任何Unicode编码的字符.
1 | |
指标类型
Prometheus定义了4种不同的指标类型(metric type):Counter(计数器)、Gauge(仪表盘)、Histogram(直方图)、Summary(摘要)
Counter:只增不减的计数器
Counter类型的指标其工作方式和计数器一样,只增不减(除非系统发生重置)。一般与rate函数配合使用。 例如,5分钟内状态码500的请求增长率
1 | |
Gauge:可增可减的仪表盘
Gauge类型的指标侧重于反应系统的当前状态,可增可减,如内存大小、温度变化 可通过PromQL内置函数delta()可以获取样本在一段时间返回内的变化情况, 例如,计算cpu温度在两小时内的差异
1 | |
还可以使用deriv()计算样本的线性回归模型,甚至是直接使用predict_linear()对数据的变化趋势进行预测。例如,预测系统磁盘空间在4个小时之后的剩余情况:
1 | |
使用Histogram和Summary分析数据分布情况
Histogram和Summary主用用于统计和分析样本的分布情况
1 | |
从上面的样本可以看出go_gc了35584次,总耗时120.343974286s,其中中位数(quantile=”0.5”)耗时0.000633772,百分75({quantile=”0.75”})的耗时为0.00229368
1 | |
两种的差异是:
- summary类似P95/P99的请求时间(响应时间),histogram是柱状图
- Histogram 需要通过
_bucket 设定分布实时计算 quantile, 而 Summary 直接存储了 quantile 的值
PromQL操作
可直接查阅官方文档:初识PromQL - prometheus-book
三、prometheus+grafana
在进行实操之前可以先看下官方文档
1、设置面板的变量
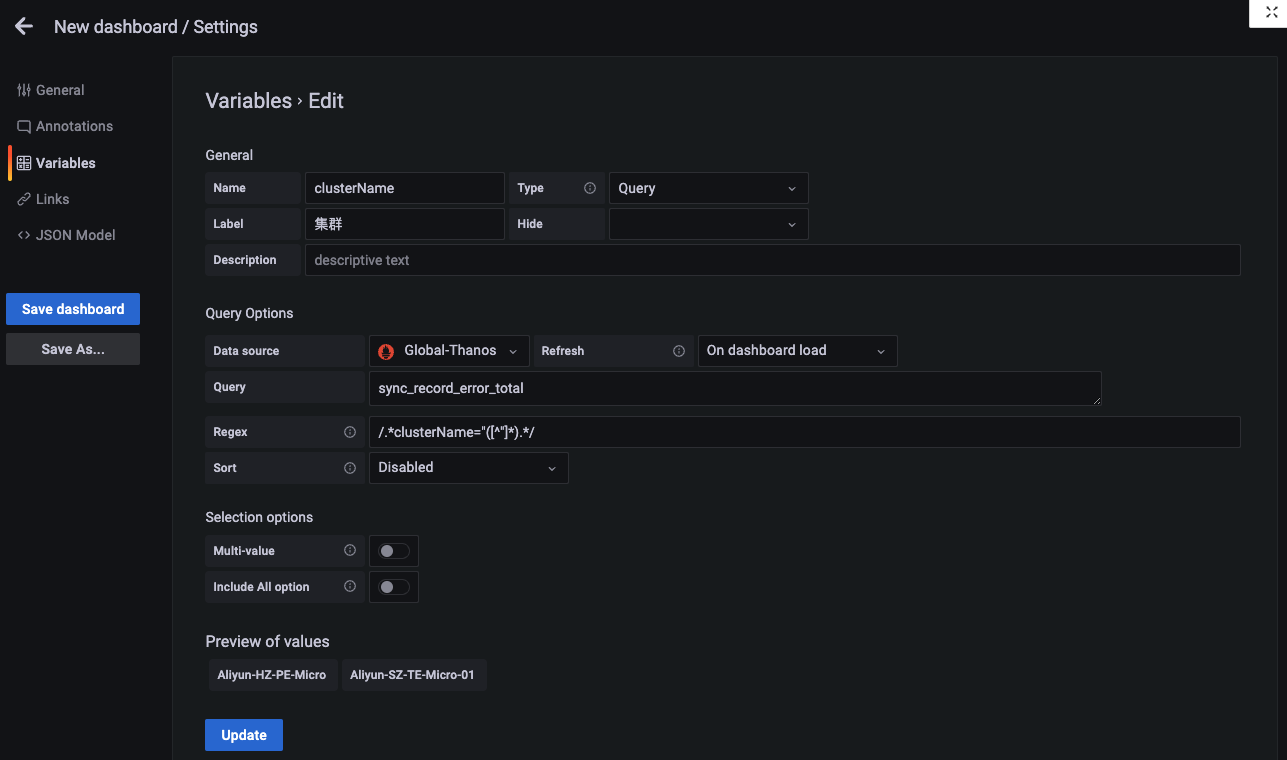

2、设置图表查询条件
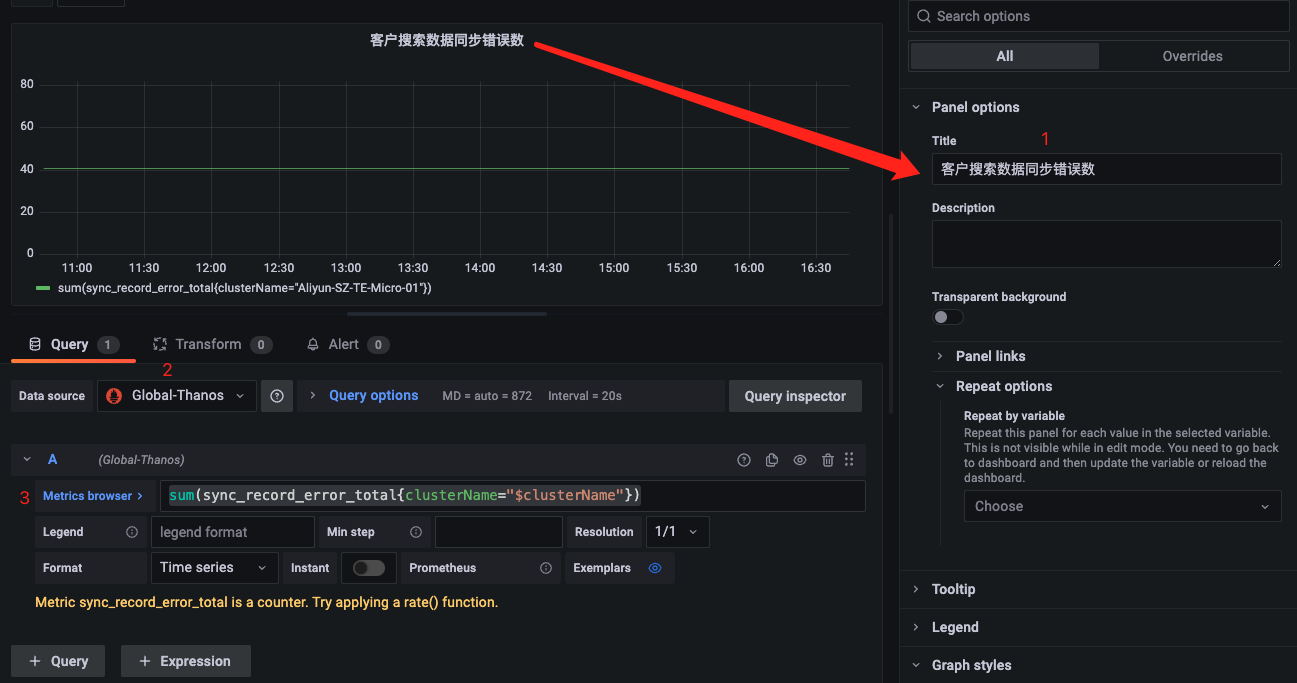 可以看到我们的查询条件是
可以看到我们的查询条件是
1 | |
利用了PromQL的聚合操作sum,统计集群内同步错误数,如果不适用sum的话,查询出来的图表是集群下每个实例对应的错误数。 从上面可以看出来,通过简单的一条查询语句,我们就可以渲染出所需的图表,也不需要额外的配置,所以由此可以感知prometheus+grafna的强大之处,而且学习成本相对还是挺低的。 当然,我们也可以配合prometheus一些内置函数或者其他聚合函数来实现更多的图表,可以通过grafana上的设置来达到我们想要的渲染效果,这里就不在一一演示,感兴趣可以去查阅对应的官方文档。
四、如何使用
这里只演示prometheus go客户端的使用
1、定义指标类型并注册:
1 | |
2、上报指标:
1 | |
3、通过框架暴露的指标接口查看
htt://*/metrics


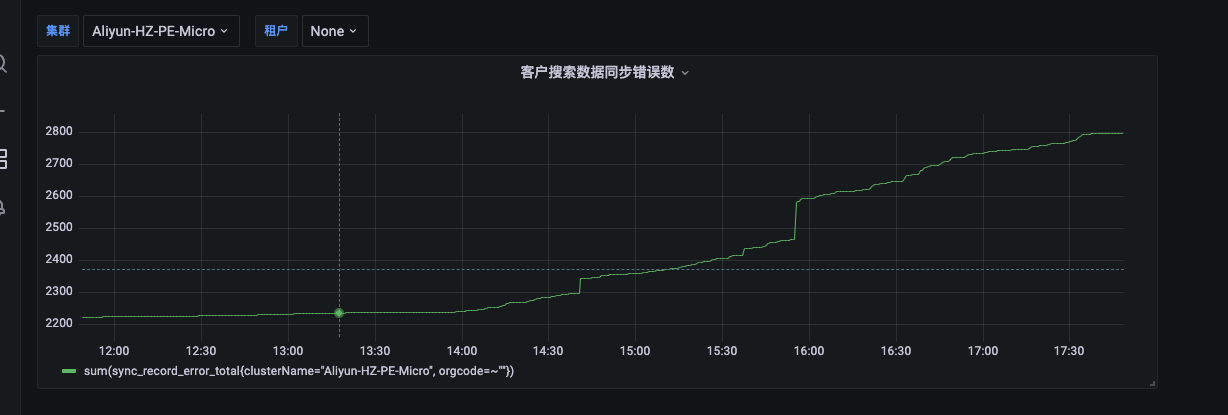
4、grafana配置效果
参考: